Your AI Agent's Memory is a Liability: Why Flat RAG Fails at Scale
- Stephen Jones
- Ai , Aws
- March 25, 2026
Table of Contents
I asked my agent to find a deployment guide. It loaded 47 documents, burned 23,000 tokens, and returned the wrong one.
That was the moment I stopped trusting RAG as a memory system for AI agents. I am not alone. Industry data shows 72 to 80 percent of enterprise RAG implementations underperform or fail within their first year, and over half of all enterprise AI failures in 2025 were RAG-related. Not because vector search is broken. It works fine for what it was designed to do: find similar text chunks. But similarity is not understanding. And dumping every vaguely related chunk into a context window is not memory. It is an expensive, unreliable approximation of one.
This post is the first in a series about building something better. I spent three days, 114 commits, and five build phases constructing an AWS-native context database inspired by ByteDance’s OpenViking project. The result is a system where agents skim before they read, navigate a structured knowledge hierarchy, and use 75 to 85 percent fewer tokens per query.
But before I show you how it works, I need to explain why the default approach fails.
The Flat RAG Problem
The standard RAG pipeline looks like this: chunk your documents, embed them, store the vectors, and at query time retrieve the top-N most similar chunks. It is elegant, well-understood, and the default recommendation in every AI framework tutorial.
It is also fundamentally wrong for agent memory.
Vector search returns chunks, not understanding. When you chunk a 20-page architecture document into 512-token pieces, you lose the structure that made it useful. The chunk about VPC design has no relationship to the chunk about IAM policies three pages later, even though they are part of the same security architecture. The agent gets fragments without context.
Every query loads N chunks regardless of relevance. If you configure top-5 retrieval, you get five chunks every time. Five chunks when you ask about S3 lifecycle policies. Five chunks when you ask what day it is. The system has no mechanism to say “I have nothing useful for this query” or “one result is sufficient.” It always loads the same amount.
There is no way for the agent to skim before committing tokens. In a flat RAG system, retrieval is all-or-nothing. The agent cannot glance at a summary to decide if a document is worth reading in full. Every retrieved chunk goes straight into the context window at full resolution. A human researcher would scan the table of contents first. RAG skips that step entirely.
Cost scales linearly with corpus size. As your knowledge base grows, the chunks get more numerous, the results get noisier, and the context window fills with increasingly marginal content. I ran the numbers on a modest 10-document corpus: flat RAG loads approximately 4,500 tokens of full content for a single query. Across hundreds of documents and dozens of queries per session, that adds up fast.
What ByteDance Figured Out
In mid-2025, ByteDance open-sourced OpenViking, a context database that treats agent memory as a first-class architectural concern. The core insight is deceptively simple: give agents the same tools humans use to navigate large information spaces.
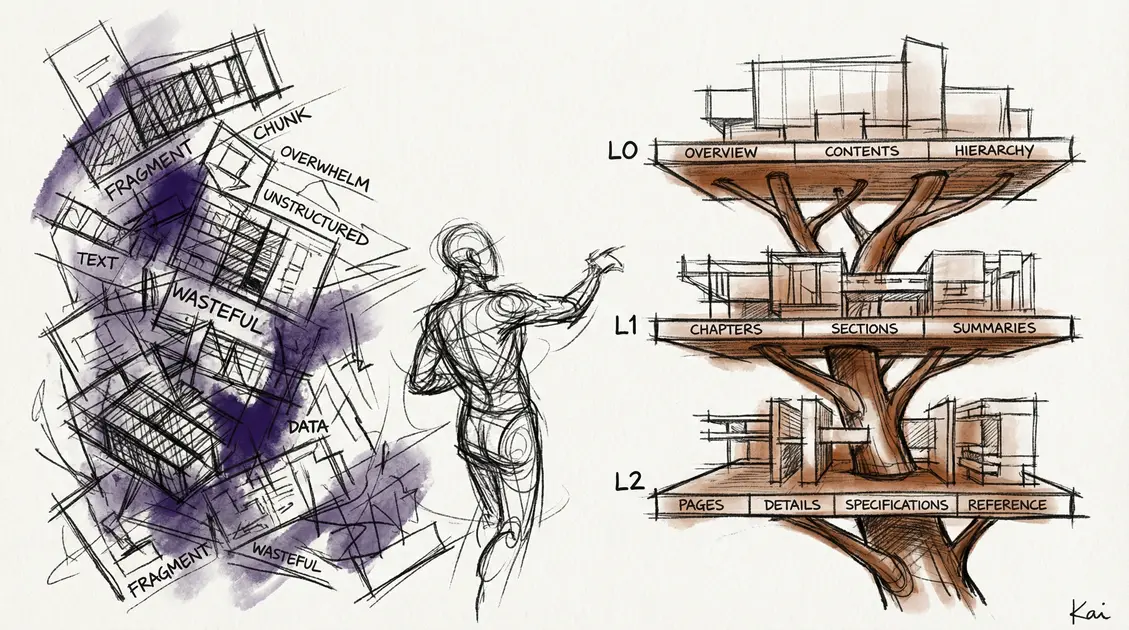
When you pick up a technical book, you do not read it cover to cover. You scan the table of contents. You read the chapter abstracts. You drill into the specific section you need. OpenViking formalises this pattern into three tiers:
- L0 (Abstract): A 100-token summary of the document. Cheap to scan, enough to decide if it is relevant.
- L1 (Overview): A structured breakdown of key sections, roughly 2,000 tokens. Enough to understand the document’s scope and find the right section.
- L2 (Full Content): The complete document. Only loaded when the agent has already confirmed it needs this specific piece of information.
The retrieval pattern becomes scan, decide, load. The agent searches and gets back L0 abstracts. It reads the abstracts (costing a few hundred tokens for ten results) and decides which one or two documents are actually relevant. Then it loads only those at L2.
I tested this on the same 10-document corpus. Flat RAG: approximately 4,500 tokens. VCS initial scan using L0 abstracts: under 800 tokens. After drilling into the two most relevant documents at full depth: roughly 1,500 tokens total. That is a 65 to 70 percent reduction on a small corpus. OpenViking’s own benchmarks report 75 to 85 percent savings at larger scales, which tracks with what I have observed.
The other key insight is hierarchy. Documents in OpenViking live in a viking:// namespace, organised into directories. When you add a document, the system automatically generates a parent summary by synthesising the abstracts of all children in that directory. This means the agent can search at the directory level (“what do I know about AWS security?”) without loading any individual document. Hierarchical navigation replaces brute-force similarity search.
Why I Built This on AWS
OpenViking is designed to run on its own infrastructure. I wanted the same capabilities on AWS primitives, with pay-per-use pricing and zero standing infrastructure.
The cost arithmetic was compelling. OpenSearch Serverless, the obvious choice for a managed vector store, starts at two OCUs minimum: $345.60 per month before you store a single vector. For a personal project and proof of concept, that is absurd. S3 Vectors, which AWS launched in 2025, costs $0.06 per GB per month for storage plus $0.35 per million queries. Combined with DynamoDB for the hierarchy metadata and Bedrock for summarisation and embeddings, the entire stack runs on pay-per-use with no minimums.
The architecture I built, which I am calling the Viking Context Service (VCS), maps OpenViking’s concepts onto AWS services:
| Concern | AWS Service | Cost Model |
|---|---|---|
| L0/L1 metadata + hierarchy | DynamoDB | Per-request |
| L2 full content | S3 | Per-GB stored |
| Vector embeddings | S3 Vectors | $0.06/GB/mo |
| Summarisation | Bedrock (Nova Lite) | Per-token |
| Fast inference | Bedrock (Nova Micro) | Per-token |
| Embeddings | Bedrock (Titan V2) | Per-token |
| Orchestration | Lambda + SQS | Per-invocation |
The entire stack deploys with a single cdk deploy command. Eight CDK constructs, eight Lambda functions, and SQS queues for asynchronous parent rollups and memory bridging. No containers, no clusters, no minimum commitments.
Where AWS Bedrock AgentCore Memory Fits
While building VCS, AWS launched Bedrock AgentCore Memory, a managed service for agent memory. It is worth understanding what it does and does not do, because the two systems solve different problems.
AgentCore Memory is excellent at session continuity: “what did we talk about?” It automatically extracts facts, preferences, and patterns from conversations using four built-in strategies (semantic, summary, user preference, and episodic). It handles deduplication, consolidation, and retrieval. The pricing is aggressive: $0.25 per 1,000 events ingested, $0.75 per 1,000 memories stored. At proof-of-concept scale, that undercuts a DIY solution by orders of magnitude because you avoid the OpenSearch Serverless minimum.
What AgentCore Memory does not do is structured knowledge navigation. It has no hierarchical namespace, no L0/L1/L2 tiers, no concept of parent rollups or directory-level summaries. It is a memory service, not a knowledge base.
The complementary architecture looks like this: VCS for the structured knowledge base (documents, domain expertise, reference material) and AgentCore Memory for conversation continuity (session context, user preferences, learned patterns). In a later post in this series, I will show how VCS uses AgentCore’s self-managed strategy as a bridge between the two systems.
The 3-Day Sprint
I built VCS in three days using the Get Shit Done framework I wrote about earlier — describe what you want, decompose it into phases, and let the agent execute. 114 commits across five phases:
- Data model and ingestion pipeline. DynamoDB schema, S3 storage, Bedrock summarisation. A single document goes in, three tiers come out.
- Retrieval with drill-down. The recursive search algorithm that starts broad and narrows, blending embedding similarity with hierarchical scores.
- Session memory. Session tracking, structured message logging, and memory extraction at session end.
- Filesystem operations. The
viking://namespace: list, tree, move, delete, with proper consistency guarantees (delete the index first, then the source). - CDK infrastructure. Eight constructs covering data, compute, API, gateway, observability, hosting, synthetics, and evaluation. IAM policies, API Gateway routes, the full deployment stack.
Each phase was independently deployable. The showcase scripts run end-to-end: ingest three documents, search them, demonstrate token savings, commit a session, and verify memory extraction. The entire test suite passes in under a minute.
What is Coming in This Series
This is Part 1 of a five-part series:
- Part 2: Architecture Deep Dive. The DynamoDB schema, the drill-down retrieval algorithm, and why bottom-up parent rollups via SQS are the key to keeping the hierarchy fresh.
- Part 3: Session Memory and Extraction. How VCS turns conversations into persistent, searchable knowledge. The four-strategy extraction model and deduplication pipeline.
- Part 4: CDK Infrastructure. Deploying the full stack from zero. IAM policies, API Gateway configuration, Lambda sizing, and cost projections at various scales.
- Part 5: AgentCore Memory Integration. Using Bedrock AgentCore Memory as the conversation layer alongside VCS as the knowledge layer. Self-managed strategies as the bridge.
If you are building agents that need to remember things, and you have been frustrated by the limitations of flat RAG, I hope this series gives you a practical alternative. The techniques are not theoretical. They are running in production, handling real queries, and saving real tokens. I plan to open source the code once the series is complete.
In Part 2, I will walk through the architecture that makes all of this work.
Sources and Acknowledgements
The RAG failure statistics come from UC Strategies’ Standard RAG Is Dead analysis and mmntm.net’s RAG Bifurcation research. Letta’s RAG is Not Agent Memory articulates the same thesis from a different angle and is worth reading. The OpenViking project documentation and BSWEN’s analysis of the L0/L1/L2 model informed the tiered context design. AgentCore Memory details are from the AWS ML Blog and official documentation.