AWS IP Ranges, Visualised
- Stephen Jones
- Aws , Building
- May 6, 2026
Table of Contents
AWS publishes a JSON file every day that nobody reads. It’s at ip-ranges.json. 2.4MB, no story.
If you’ve worked on contact-centre migrations, security-group automation, firewall allow-lists, or anything else that needs to know whether an IP belongs to AWS, you’ve grabbed that file at some point. You may have even diff’d two versions to see what changed.
But the file is a snapshot. It tells you what AWS looks like today. It doesn’t tell you which regions are growing, which services are quietly emerging, when AWS announced South America (Chile), or how fast GovCloud is expanding compared with commercial.
That data is all there. It’s just sitting in 21 months of git history that nobody’s bothered to query.
I went and queried it.
The Mirror Repo Doing All the Work
A couple of years back I set up a small repo called aws-ip-ranges. It does one thing: every day at noon UTC, a GitHub Action pulls https://ip-ranges.amazonaws.com/ip-ranges.json and commits it back to the repo.
That’s it. That’s the whole architecture. No database. No cron server. No infrastructure to monitor. A workflow file and a free GitHub Action runner.
The output: 650+ commits over 21 months, each one a complete daily snapshot of AWS’s IP topology.
Until last week, the only consumer of that data was a 465KB auto-generated README. Every story the data could tell was invisible.
Git History Is a Free Time-Series Database
Here’s the thing nobody tells you: if you mirror a structured JSON file daily into a git repo, you’ve built a time-series database for free.
git log is your index. git show <sha>:ip-ranges.json gives you the value at any point in time. git diff gives you change events. The storage cost is whatever GitHub charges you for a public repo, which is zero.
Most people stop at the snapshot. The snapshot is fine if all you want is “what does AWS look like today”. The interesting questions are the temporal ones, and the temporal data is sitting there for the asking.
A few questions I can now answer in seconds:
- When did
eusc-de-east-1, the European Sovereign Cloud, first appear in AWS’s IP space? November 2023. - Which regions are accelerating versus stable? GovCloud is up about 31% year-on-year, fastest of the lot.
- What’s the largest single-day diff in the last 21 months, and what was it? Two consecutive 2,000+ line commits in February 2026, lining up almost exactly with
sa-west-1andmx-central-1going from zero prefixes to populated. - Which services quietly emerged in the long tail?
AURORA_DSQLshowed up with 19 prefixes, the first hint that Amazon’s distributed SQL service is now real infrastructure rather than a slide.
None of that comes from the snapshot. All of it comes from the history.
Eight Sections That Make the Invisible Signal Legible
I built the dashboard at https://sjramblings.github.io/aws-ip-ranges/. It runs on GitHub Pages, deploys after every daily AWS pull, costs nothing, and turns 21 months of git history into something you can actually look at.
There are eight sections. Each one answers a question the snapshot can’t:
- Hero: current totals, animated, with a sparkline showing how the prefix count has grown.
- Timeline: every commit plotted on a brushable D3 chart, with major-event markers (commits over 1,500 lines) and dots at the date each new region first appeared.
- Region Atlas: 43 cards, sortable by size or growth rate. Click any one to see its prefix count over time.
- Service Composition: stacked area chart of the top 10 services, with a long-tail strip showing which services crossed the 10-prefix and 100-prefix thresholds and when.
- Compliance and Edge Lens: Commercial vs GovCloud vs China vs GLOBAL year-on-year growth, on the same chart so the divergence is visible.
- Activity Calendar: GitHub-style heatmap of the last 365 days, but coloured by diff size, not commit count. AWS’s actual update rhythm becomes legible. Quiet weekends. Occasional batch days.
- Prefix Explorer: searchable, filterable, sortable table of every current prefix, with CSV export.
- Stories: auto-generated narrative cards. The Feb 2026 mega-commits, the new regions of the last year, the GovCloud divergence, the long-tail service emergences.
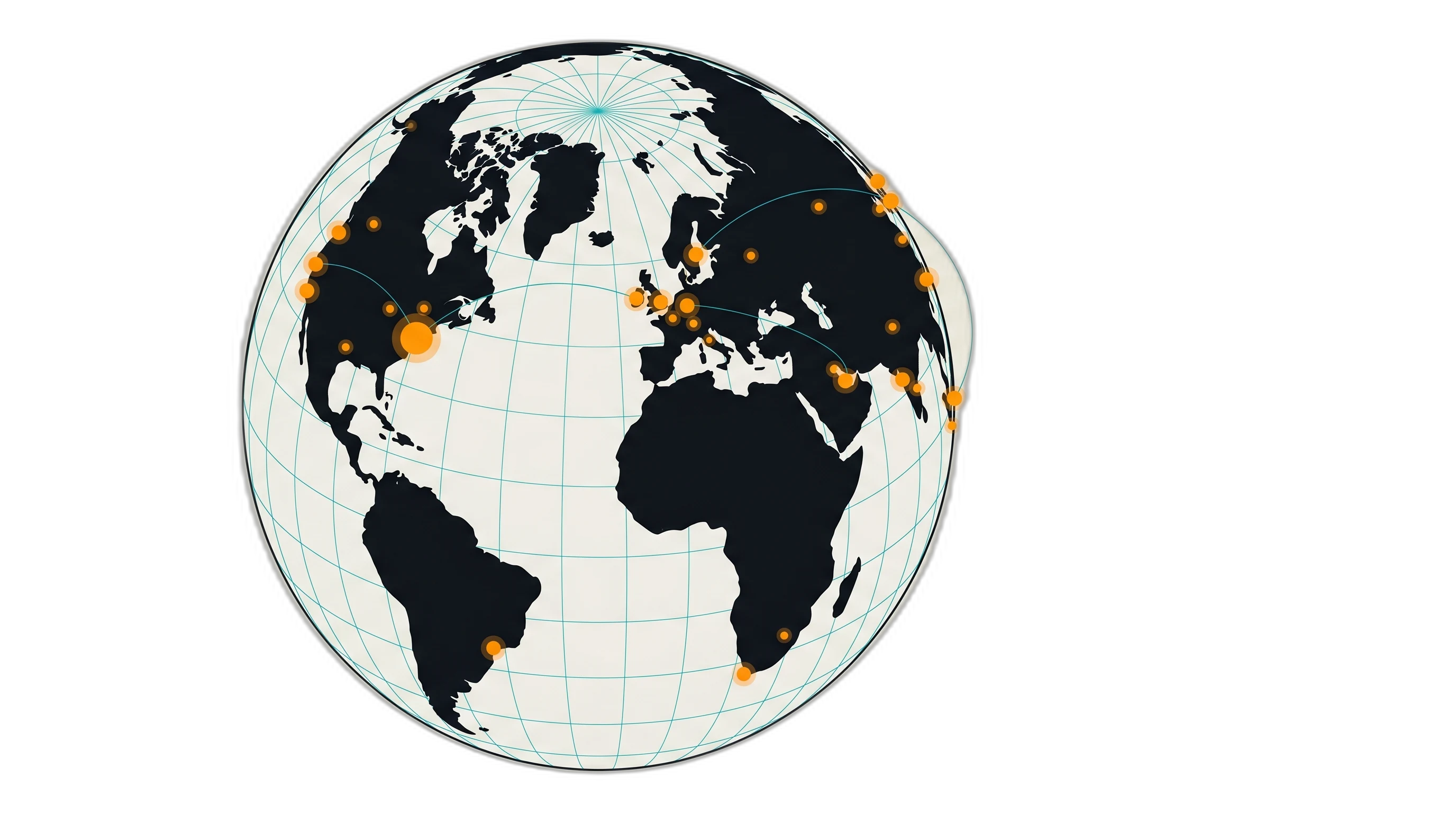
There’s also a separate page at /globe.html: a draggable D3 orthographic projection of the world, with every announced AWS region pinned and sized by current prefix count. Same git-history data, different framing.
Building the Pipeline: jq Earned Its Keep
The interesting engineering wasn’t the React. The interesting engineering was the data extractor.
The naive approach: walk the git log, read each commit’s full ip-ranges.json into the JS heap, aggregate. That’s 2.4MB × 650 commits = roughly 1.5GB of stdout streaming through a Bun subprocess. The first version of the script hung at 0.3% CPU after 15 minutes. Possible? Sure. Optimal? Not even close.
The fix was small and obvious in hindsight: aggregate inside jq before the data leaves the subprocess. A single shell pipeline per commit:
git show <sha>:ip-ranges.json | jq -c '<aggregator>'
The aggregator extracts only the per-region and per-service prefix counts. That’s a few hundred bytes per commit instead of 2.4MB. The full 650-commit run drops from “hung indefinitely” to 16 seconds.
Real-world note: piping git show straight into a jq child process via Node’s child_process.pipe() hit EPIPE errors under concurrency. The fix was running the pipeline through /bin/sh -c so the shell handles the buffering, not Node. Sometimes the boring abstraction is the right one.
The output is five small JSON files:
timeline.json per-commit aggregates
regions.json per-region time series
services.json per-service time series
events.json major commits + first-appearances with auto-generated narrative
current.json full latest snapshot for the explorer
A GitHub Action runs after the existing daily AWS pull, regenerates those five files, builds the Vite static bundle, deploys via actions/deploy-pages. The whole thing lives inside one repo. Zero external infrastructure.
The Day My CI Shipped One Datapoint Instead of 650
The first deploy went green. The site was live. Every chart was rendering. Every chart was also rendering one datapoint.
Here’s what happened. The extractor uses an incremental cache. It remembers the last commit it processed (last-extracted-sha) and only walks new commits since then. The cache also stores the prior aggregated snapshots so it doesn’t have to redo work.
I’d committed the SHA file by accident, but gitignored the snapshots cache. On a fresh CI checkout, the extractor saw a SHA, asked git for “commits since that SHA”, got back zero new commits (the daily AWS pull hadn’t bumped anything yet), found no prior snapshots, and dutifully wrote one snapshot to disk.
That’s… not good.
Codex bot caught it in PR review and called the exact bug. The fix was small: treat the cache as a both-or-neither pair. If both files are present, use the cache. If only one is present, fall back to a full rebuild and log the reason. The full rebuild takes 16 seconds. Cheap insurance.
The deeper lesson: any cache with two coupled artefacts on disk needs to verify both exist, every time. Asymmetric cache state is the bug nobody sees coming, because every component is doing its job correctly. The mistake is at the contract.
What 21 Months of AWS History Actually Tells You
Once the data was visible, a few things landed:
AWS doesn’t launch many new services. It deepens existing ones. AMAZON and EC2 services together account for around 75% of all prefixes. The growth is in those two, not in a parade of new categories. The long tail is small in absolute terms but where the strategy lives. AURORA_DSQL emerging quietly with 19 prefixes is more strategically significant than another 500 prefixes added to EC2.
GovCloud is growing faster than commercial. That tracks regulated-workload migration. If you read AWS only through the Bedrock and Q announcements, you’d miss it.
The GLOBAL region (CloudFront, Route53, WAF, GlobalAccelerator) is up around 19% year-on-year. AWS’s edge story is bigger than its keynote real estate suggests.
Region launches show up as 2,000-line commit spikes before AWS announces them. The two consecutive mega-commits in February 2026 lined up with sa-west-1 (Santiago, Chile) and mx-central-1 (Querétaro, Mexico) going from zero prefixes to populated. The git-history signal led the press release by days.
None of this is exotic infrastructure. It’s a JSON file and a daily commit.
The Bigger Picture
The pattern isn’t really about AWS IP ranges. It’s about what happens when you treat structured public data as a stream and let git accrete the history.
Most major vendors publish structured data daily that nobody mirrors. AWS has at least four worth tracking: ip-ranges.json, the Bedrock model-availability matrix, the regional services list, and the pricing API. Cloudflare publishes its own IP ranges. GCP publishes a netblocks endpoint. Azure does too. Each of those is a free time-series database waiting for somebody to set up a daily mirror.
The leverage is enormous: a six-line GitHub workflow plus 200 lines of extractor plus a Vite static site, and you’ve turned a vendor’s invisible daily output into a permanent, queryable, visualisable record. It costs nothing and runs forever. The vendor doesn’t need to know. They might even thank you for it.
If you’re working in cloud, the bigger move isn’t building one dashboard. It’s noticing how much of the data you actually need is already being published, and just isn’t being captured over time.
Real-World Notes
A few honest caveats:
- Some regions are missing from the globe page because I didn’t have reliable city centroids for every announced AWS region. The “not placed” footer in the sidebar keeps that honest. Adding a new region is one line in the coordinates file.
- The major-event detection threshold (1,500 lines) is a guess. It catches the obvious region launches but probably misses smaller meaningful events.
- This is one practitioner with a free GitHub plan. It is not a production-grade observability product. The point is the leverage of the pattern, not the polish of any one rendering.
Sign-off
The site is at https://sjramblings.github.io/aws-ip-ranges/. The repo is at https://github.com/sjramblings/aws-ip-ranges. The whole thing was built across a couple of evenings and now updates itself.
If you’ve been mirroring vendor JSON without visualising it, this is your nudge. If you haven’t been mirroring vendor JSON at all, today is a perfectly good day to start.
I hope someone else finds this useful.
Cheers.