AWS Bedrock AgentCore Policy & Evaluations: AI Agent Governance at Scale
- Stephen Jones
- Ai , Aws
- December 13, 2025
Table of Contents
Many organisations are rushing into deploying AI agents with the same enthusiasm they had for serverless in 2016, great technology, terrible operational discipline. The pattern is predictable: build a proof-of-concept that works brilliantly in a demo, deploy it cautiously to production, then discover you have no idea how to govern what it’s actually doing once users interact with it at scale.
AWS just announced two features in Amazon Bedrock AgentCore: Policy (preview) and Evaluations (preview). These aren’t incremental feature releases. They’re the operational controls every team deploying agents should have had from the beginning.
Here’s the hard truth: if you’re deploying AI agents without policy controls and continuous evaluation, you’re not running production infrastructure. You’re running an experiment you hope doesn’t break something important.
The Problem: Agents Are Autonomous by Design
Traditional software is deterministic. You write code, test it, deploy it. Behavior is predictable. When something breaks, you trace the execution path, find the bug, fix it.
AI agents don’t work that way. They’re designed to be autonomous to make decisions, call tools, access data, and adapt based on context. That autonomy is what makes them useful. It’s also what breaks traditional governance models.
What actually happens in production:
- An agent calls a third-party API you didn’t anticipate
- It accesses a database table with PII because the context suggested it was relevant
- It chains tool calls in ways your initial testing never covered
- It generates responses that are technically correct but violate your compliance policies
None of these are “bugs.” They’re emergent behaviors from autonomous systems operating at scale. Without governance mechanisms in place before deployment, you discover these issues through customer complaints, compliance violations, or worse.
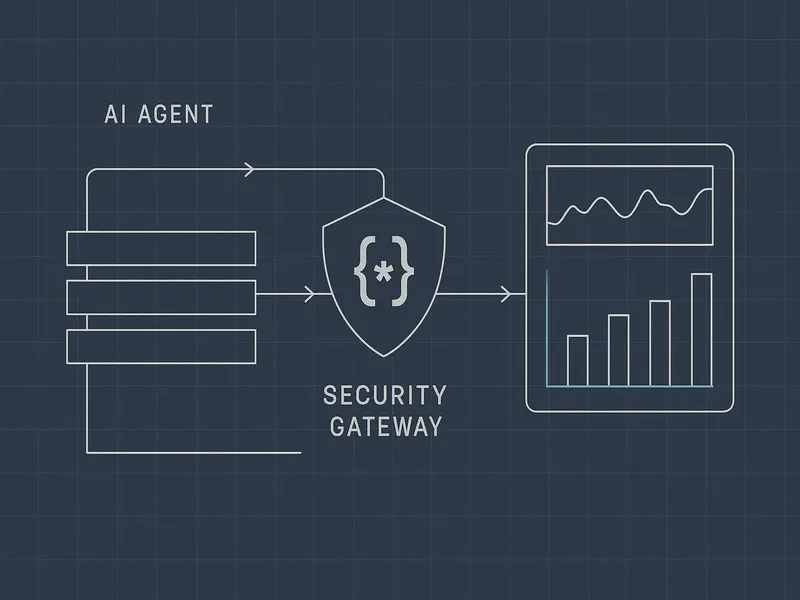
Policy: Real-Time Guardrails for Agent Actions
AWS Bedrock AgentCore Policy solves a specific problem: how do you define boundaries for what agents are allowed to do without hand-coding every constraint?
The mechanism is straightforward:
Write policies in natural language. Instead of coding authorization logic, you describe what agents can and can’t do. “Allow agents to read customer data, but not financial data.” “Permit API calls to internal services, block third-party integrations.”
AWS translates to Cedar. Cedar is AWS’s open-source policy language—the same system powering AWS Verified Access and Amazon Verified Permissions. Your natural language policy converts to formal Cedar rules: machine-readable, auditable, enforceable.
AgentCore Gateway intercepts every tool call. Every agent action flows through the Gateway. Policy evaluates each call before it executes. Violates policy? Blocked. Allowed? Proceeds.
The key difference: enforcement happens at the infrastructure layer, not in your application code. You don’t trust the agent to respect boundaries. The infrastructure enforces them.
Why This Matters for Production Deployments
Concrete example: you deploy an AI agent to help customer support teams resolve billing issues. The agent has access to customer account data, transaction history, and payment methods.
Without policy controls, the agent could access any customer record (even unrelated to the current ticket), trigger refunds via API without approval, or expose PII in cached logs.
With AgentCore Policy, you define:
- “Agent can only access data for the customer_id in the current session context”
- “Agent can query billing data but cannot execute payment operations”
- “All tool calls must log context for audit purposes”
Now the agent operates within defined boundaries. When a tool call violates those boundaries, it’s blocked before reaching your systems. That’s the difference between an experiment and production infrastructure.
Evaluations: Continuous Quality Monitoring for Agent Behavior
Policy solves authorization. Evaluations solve quality.
AgentCore Evaluations includes 13 built-in evaluators that continuously monitor agent performance based on real-world interactions:
- Helpfulness: Is the agent actually solving the problem?
- Tool selection accuracy: Is it choosing the right tools?
- Correctness: Are responses factually accurate?
- Safety: Is the agent staying within safety guidelines?
You can also build custom evaluators for business-specific dimensions: response tone, domain-specific accuracy, brand voice adherence. Evaluations let you define those metrics and track them continuously.
All metrics feed into Amazon CloudWatch. You’re not guessing whether your agent is performing well—you’re measuring it.
From Testing to Monitoring
Traditional software testing happens before deployment. Write tests, they pass, deploy.
AI agents don’t work that way. You can’t anticipate every interaction. Behavior emerges from the combination of model inference, tool calls, user context, and external data. You can test common scenarios. You can’t test everything.
Evaluations shift from testing before deployment to continuous monitoring after deployment. Instead of predicting edge cases, you monitor real-world behavior and catch issues as they happen.
This is the same operational maturity shift that happened with observability in microservices: you don’t prevent every failure, you detect, measure, and respond quickly.
Log Mode: Validate Before You Enforce
When you deploy a policy to AgentCore Gateway, choose between enforce mode (block violating actions) or log mode (emit logs but allow actions).
Log mode lets you validate policies without breaking legitimate agent behavior. Deploy a policy, watch the logs, see what would have been blocked, refine it, then flip to enforce mode.
This is pragmatic: the difference between a feature that sounds good and a feature you’ll use.
What This Means for Your AI Agent Strategy
1. Start with Policy, Not Permissions
Most teams approach agent security like traditional application security: IAM roles, resource permissions, network isolation. Necessary but insufficient.
Agents operate at a higher level of abstraction. They need guardrails for when and how they use tools, not just permission to access them. Policy gives you that layer.
Define your policies early. What are the boundaries? What data can agents access? What actions are off-limits? Write these as natural language policies. Let AgentCore translate them to Cedar.
2. Treat Evaluations as a First-Class Metric
You wouldn’t run a web application without monitoring response times, error rates, and throughput. Don’t run an AI agent without monitoring helpfulness, accuracy, and tool selection.
Build evaluation dashboards into your operational workflows. If helpfulness drops, investigate. If tool selection degrades, refine your agent. Treat quality metrics the same way you treat performance metrics.
3. Start with Log Mode
Don’t deploy policies directly into enforce mode. Start with log mode. Watch what your agent does in production. See what would have been blocked. Refine policies based on real behavior, not hypothetical scenarios.
Once confident, flip to enforce mode. This reduces the risk of over-constraining your agent and breaking legitimate use cases.
4. Design for Auditability
AgentCore Policy creates an audit trail. Every tool call flows through the policy engine. You can log policy decisions, track what was allowed, trace why actions were blocked.
For regulated industries—healthcare, finance, government—this is critical. You’re not just saying “the agent is governed.” You’re proving it with logs.
The Bigger Picture
AWS is betting the next wave of AI adoption isn’t about better models—it’s about better operations. AgentCore Policy and Evaluations are that bet.
Teams that succeed with AI agents won’t have the most sophisticated models. They’ll have the discipline to treat agents like production infrastructure: governed, monitored, auditable.
If you’re building agents today, ask yourself:
- Do you have clear boundaries for what your agents can do?
- Can you prove compliance when an auditor asks how your agent made a decision?
- Do you know when agent quality is degrading before users complain?
If the answer is no, you’re not ready for production. AgentCore Policy and Evaluations give you the infrastructure to answer yes.
Hope Someone Else Finds This Useful
I’ve seen too many teams rush into AI agents without the operational controls they need. The technology is exciting. Discipline matters more.
AWS Bedrock AgentCore Policy and Evaluations aren’t flashy. They’re the unglamorous infrastructure work that separates a demo from a system you can run your business on.
If you’re evaluating AI agent platforms, put governance at the top of your criteria list. Not just “does it work,” but “can I control it, monitor it, and audit it at scale.”
Want to explore further? Check out the Amazon Bedrock AgentCore documentation and the AgentCore FAQs.
Related reading:
- AWS Config Now Tracks AgentCore Gateways and Memory — Config support closes the governance visibility gap for AI agent deployments.
- AWS MCP Strategy Guide: The Interesting Parts — Token isolation and golden path abstractions complement AgentCore policy enforcement.
- n8n to AWS Bedrock AgentCore — Prototype agent logic in hours, then deploy to AgentCore with policy controls.
Sources:
- Amazon Bedrock AgentCore adds quality evaluations and policy controls - AWS Blog
- Amazon Bedrock AgentCore now includes Policy, Evaluations (preview) - AWS What’s New
- Amazon Bedrock AgentCore - AWS
- AWS goes beyond prompt-level safety with automated reasoning in AgentCore - VentureBeat
- New Amazon Bedrock AgentCore capabilities power the next wave of agentic AI development - About Amazon


